
Water Material by Address: A Comprehensive AWS-Powered Solution
As a full-stack developer passionate about creating impactful solutions, I recently built a Water Service Line Identification tool for a regional utility authority. This project showcases my ability to develop complex, user-friendly applications while leveraging cloud technologies to create efficient, scalable solutions for real-world problems.
Project Overview and Demonstration
The utility authority, a multi-service utility provider serving a mid-sized city in Tennessee, needed a tool that would allow their customers to easily access information about their water service materials. The result is a web application that enables users to search for their address and instantly view details about their water service line materials, including whether any replacements or verifications are needed.
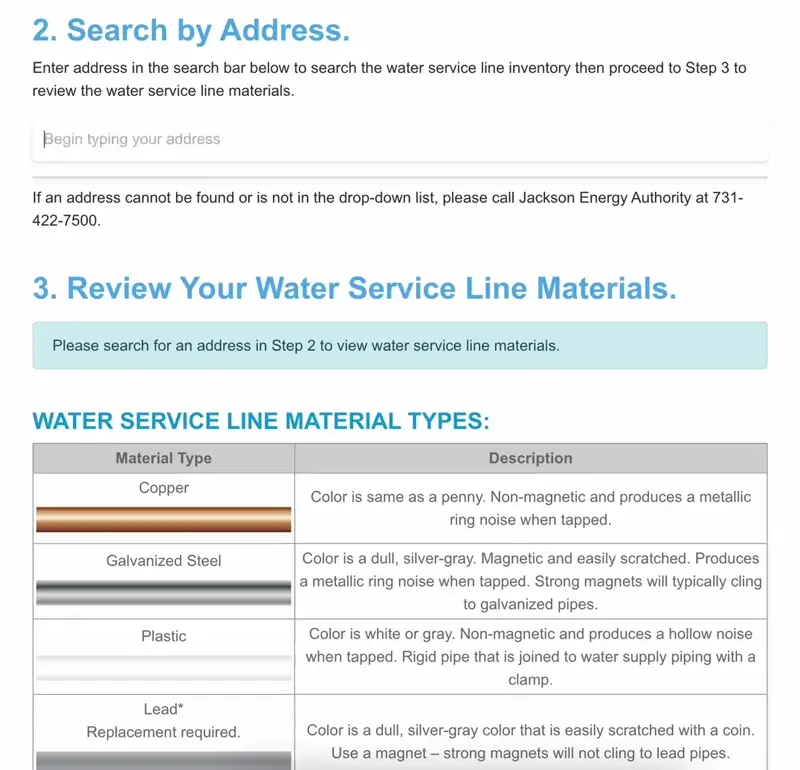
As you can see, users can simply start typing their address, and the application provides real-time suggestions. Once an address is selected, the tool displays comprehensive information about both the customer-owned and utility-owned portions of the water service line.
Technical Stack: Leveraging the Power of AWS
To create a robust, scalable, and secure solution, I chose a modern, cloud-based architecture:
- Frontend: Alpine.js for reactive UI components
- Backend API: Express.js deployed on AWS Elastic Beanstalk
- Database: AWS RDS (PostgreSQL)
- ETL Process: AWS Lambda with Python
- Infrastructure: AWS VPC for enhanced security and performance
This stack allows for a scalable architecture that can handle varying loads efficiently while maintaining high levels of security and performance.
Deep Dive into the Code
Backend API: Elastic Beanstalk and Express.js
The core of the backend is an Express.js application deployed on AWS Elastic Beanstalk. This setup provides a scalable and easily manageable environment for our API:
// server.js
const express = require('express');
const { Pool } = require('pg');
const cors = require('cors');
require('dotenv').config();
const app = express();
app.use(cors());
// Configure database connection using environment variables
const pool = new Pool({
// Configuration loaded from environment variables
});
// Address search endpoint
app.get('/api/addresses', async (req, res) => {
const query = req.query.q;
if (!query) {
return res.status(400).json({ error: 'Query parameter is required' });
}
try {
const result = await pool.query(
'SELECT address_data FROM addresses WHERE address ILIKE $1',
[`%${query}%`]
);
res.json(result.rows);
} catch (error) {
console.error('Error fetching addresses');
res.status(500).json({ error: 'Internal server error' });
}
});
// Water service information endpoint
app.get('/api/water_service_info', async (req, res) => {
const locationId = req.query.location_id;
if (!locationId) {
return res.status(400).json({ error: 'Location ID parameter is required' });
}
try {
const result = await pool.query(
'SELECT service_info FROM water_services WHERE id = $1',
[locationId]
);
if (result.rows.length === 0) {
return res.status(404).json({ error: 'No data found' });
}
res.json(result.rows[0]);
} catch (error) {
console.error('Error fetching water service info');
res.status(500).json({ error: 'Internal server error' });
}
});
const port = process.env.PORT || 3000;
app.listen(port, () => {
console.log(`Server is running on port ${port}`);
});
The Express.js application handles two main API endpoints, implementing proper error handling and security practices while maintaining clean, maintainable code.
ETL Process: AWS Lambda
For the nightly ETL (Extract, Transform, Load) process, we use an AWS Lambda function. Here's a look at the core implementation:
import os
import json
import logging
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""
Main Lambda handler for the ETL process
"""
logger.info("Starting ETL process")
try:
# Initialize database connection
engine = create_engine(os.getenv('DATABASE_URL'))
Session = sessionmaker(bind=engine)
session = Session()
# Process data
process_new_data(session)
session.close()
return {
"statusCode": 200,
"body": json.dumps("ETL process completed successfully")
}
except Exception as e:
logger.error(f"ETL process failed: {str(e)}")
return {
"statusCode": 500,
"body": json.dumps("ETL process failed")
}
def process_new_data(session):
"""
Process and update water service data
"""
try:
# Fetch new data from source
new_data = fetch_data_from_source()
# Transform and validate data
transformed_data = transform_data(new_data)
# Update database
update_database(session, transformed_data)
session.commit()
except Exception as e:
session.rollback()
raise e
Frontend: Alpine.js for Reactive UI
The frontend implementation uses Alpine.js to create a responsive and user-friendly interface:
<div x-data="waterService()">
<input
type="text"
x-model="query"
x-on:input="fetchAddresses()"
placeholder="Begin typing your address"
/>
<ul id="suggestions">
<template x-for="address in addresses" :key="address.id">
<li x-text="address.display_address" x-on:click="selectAddress(address)"></li>
</template>
</ul>
<div x-show="waterServiceInfo">
<h3>Water Service Information</h3>
<p>
Customer Material:
<span
x-text="waterServiceInfo.customerMaterial"
:class="getMaterialClass(waterServiceInfo.customerMaterial)"
></span>
</p>
<p>
Utility Material:
<span
x-text="waterServiceInfo.utilityMaterial"
:class="getMaterialClass(waterServiceInfo.utilityMaterial)"
></span>
</p>
</div>
</div>
<script>
function waterService() {
return {
query: '',
addresses: [],
waterServiceInfo: null,
async fetchAddresses() {
if (this.query.length < 3) {
this.addresses = [];
return;
}
try {
const response = await fetch(`/api/addresses?q=${encodeURIComponent(this.query)}`);
if (!response.ok) throw new Error('Failed to fetch addresses');
this.addresses = await response.json();
} catch (error) {
console.error('Error fetching addresses');
this.addresses = [];
}
},
async selectAddress(address) {
this.query = address.display_address;
this.addresses = [];
try {
const response = await fetch(`/api/water_service_info?location_id=${address.id}`);
if (!response.ok) throw new Error('Failed to fetch water service info');
this.waterServiceInfo = await response.json();
} catch (error) {
console.error('Error fetching water service info');
this.waterServiceInfo = null;
}
},
getMaterialClass(material) {
return {
'highlight-replace': ['Lead', 'Galvanized'].includes(material),
'highlight': material === 'Unknown',
'highlight-optional': material.startsWith('Non-Lead')
};
}
};
}
</script>
Impact and Future Enhancements
The Water Service Line Identification tool has significantly improved the utility authority's ability to inform customers about their water service materials. It has also enhanced their data collection process, as customers can submit information about previously unknown materials through the integrated plumbing survey.
Looking forward, there are several potential enhancements for the tool:
- Implement real-time updates for water service information
- Integrate with the utility's work order system for automated scheduling of replacements
- Expand the tool to cover other utility services provided by the authority
Conclusion
This project demonstrates my ability to create full-stack applications that solve real-world problems using cloud technologies. By leveraging AWS services like Elastic Beanstalk and Lambda, implementing efficient data querying, and creating an intuitive user interface, I delivered a solution that meets both technical requirements and user needs.
The Water Service Line Identification tool showcases my skills in:
- Cloud architecture design with AWS
- Deploying and managing applications with Elastic Beanstalk
- Creating ETL processes using AWS Lambda
- Database integration and optimization with RDS
- Frontend development with modern JavaScript frameworks
- API design and implementation with Express.js
- Security considerations in web application development